Filesystems for everybody!
Feb 15, 2025
lenovo
homelab
kubernetes
nfsroot
read-only-root
capabilities
Putting together a homelab Kubernetes cluster in my own stubborn way. I’m assuming a reader who’s basically me before I embarked on this little expedition, so I won’t go into minute detail about day-to-day Linux setup and administration - only the things that are new to me and have changed since I last encountered them.
- Part 0 - Best laid plans
- Part 1 - Installing the hardware
- Part 2 - Boot across the network
- Part 3 - PXE Booting Debian with an NFS Root Filesystem
- Part 4 - Filesystems for everybody!
- Part 5 - Getting a clean boot
- Part 6 - Kubernetes at last
Sections added as I actually proceed with this!
Multiple filesystems
My plan is that at boot time there will be two NFS shares:
- A read-only share
- A writeable share
The read-only share will contain most of the operating system.
The writeable share will be used (duh) whenever a worker node needs to write anything, so for instance to mount
the /var directory. In the writeable share there will be one directory for each worker node - the tricky bit
is that I want these worker-specific writeable directories to be created as needed when a worker boots up.
To achieve this I’m going to take advantage of the initramfs environment and add scripts to that to:
- Mount the writeable share (temporarily)
- If it doesn’t already exist, create the (specific) worker node’s own writeable directory
- Unmount the (general) writeable share and then mount the worked node’s own writeable directory in some way.
I’m not convinced that this is a good idea and a lot less convinced that it’s the best way, but it should work and I’m playing this game for fun not reliability.
So … I need to customise an initramfs image.
Preparing to customise the initramfs image
Working on my Ubuntu laptop (the tools are the same as for Debian due to the shared lineage), I made a working directory called ~/initrd
Then I grabbed the initrd file from the gateway server (the one I’m using to boot the worker nodes):
dcminter@kanelbulle:~/initrd$ sftp 192.168.1.158
Connected to 192.168.1.158.
sftp> cd /srv/tftp
sftp> ls
initrd.img-6.1.0-21-amd64 ldlinux.c32 pxelinux.0 pxelinux.cfg vmlinuz-6.1.0-21-amd64
sftp> get initrd.img-6.1.0-21-amd64
Fetching /srv/tftp/initrd.img-6.1.0-21-amd64 to initrd.img-6.1.0-21-amd64
initrd.img-6.1.0-21-amd64 100% 38MB 35.2MB/s 00:01
sftp> exit
dcminter@kanelbulle:~/initrd$ ls -al
total 38448
drwxrwxr-x 2 dcminter dcminter 4096 Aug 24 21:53 .
drwxr-x--- 63 dcminter dcminter 4096 Aug 24 21:52 ..
-rw-r--r-- 1 dcminter dcminter 39359954 Aug 24 21:53 initrd.img-6.1.0-21-amd64
Per a Stack Exchange question page the image file is actually two cpio files concatenated together and the second is also compressed (although for my Debian image it seemed to be with zstd rather than gzip.
I used the unmkinitramfs tool to unpack the contents of the file:
dcminter@kanelbulle:~/initrd$ unmkinitramfs initrd.img-6.1.0-21-amd64 unpacked
dcminter@kanelbulle:~/initrd$ cd unpacked
dcminter@kanelbulle:~/initrd/unpacked$ ls -al
total 16
drwxrwxr-x 4 dcminter dcminter 4096 Aug 24 21:53 .
drwxrwxr-x 3 dcminter dcminter 4096 Aug 24 21:53 ..
drwxrwxr-x 3 dcminter dcminter 4096 Aug 24 21:53 early
drwxrwxr-x 7 dcminter dcminter 4096 Aug 24 21:53 main
dcminter@kanelbulle:~/initrd/unpacked$ cd early
dcminter@kanelbulle:~/initrd/unpacked/early$ ls -al
total 12
drwxrwxr-x 3 dcminter dcminter 4096 Aug 24 21:53 .
drwxrwxr-x 4 dcminter dcminter 4096 Aug 24 21:53 ..
drwxr-xr-x 3 dcminter dcminter 4096 Aug 24 21:53 kernel
The early directory contains Intel microcode updates, and
the main directory contains the real initramfs filesystem that’s used at boot time.
I want to be sure that if I make any changes to this the problems I get are down to my own mistakes in contents of the filesystem, not the repackaging of it into a single image file, so before I make any changes I want to make sure that I can recreate a bootable image file from these contents.
Packing up the early directory with cpio (with the various find and cpio flags stolen
from Debian’s Custom Initramfs documentation:
dcminter@kanelbulle:~/initrd/unpacked/early$ find . -print0 | cpio --null --create --verbose --format=newc > ~/initrd/early.cpio
.
./kernel
./kernel/x86
./kernel/x86/microcode
./kernel/x86/microcode/GenuineIntel.bin
./kernel/x86/microcode/.enuineIntel.align.0123456789abc
14080 blocks
Then packaging up main as a cpio file (omitting a LOT of the output):
dcminter@kanelbulle:~/initrd/unpacked/early$ cd ..
dcminter@kanelbulle:~/initrd/unpacked$ cd main/
dcminter@kanelbulle:~/initrd/unpacked/main$ find . -print0 | cpio --null --create --verbose --format=newc > ~/initrd/main.cpio
.
./lib64
./init
./sbin
./usr
./usr/lib64
./usr/lib64/ld-linux-x86-64.so.2
./usr/sbin
...
./etc/ld.so.conf.d
./etc/ld.so.conf.d/libc.conf
./etc/ld.so.conf.d/x86_64-linux-gnu.conf
262725 blocks
Taking a look at the output files…
dcminter@kanelbulle:~/initrd/unpacked/main$ cd ..
dcminter@kanelbulle:~/initrd/unpacked$ cd ..
dcminter@kanelbulle:~/initrd$ ls -al
total 176860
drwxrwxr-x 3 dcminter dcminter 4096 Aug 24 21:54 .
drwxr-x--- 63 dcminter dcminter 4096 Aug 24 21:52 ..
-rw-rw-r-- 1 dcminter dcminter 7208960 Aug 24 21:54 early.cpio
-rw-r--r-- 1 dcminter dcminter 39359954 Aug 24 21:53 initrd.img-6.1.0-21-amd64
-rw-rw-r-- 1 dcminter dcminter 134515200 Aug 24 21:54 main.cpio
drwxrwxr-x 4 dcminter dcminter 4096 Aug 24 21:53 unpacked
So first I want to compress the main.cpio file - I’ll try with gzip first (at maximum compression) and go to zstd later only if I have problems:
dcminter@kanelbulle:~/initrd$ gzip --best main.cpio
dcminter@kanelbulle:~/initrd$ ls -al
total 82724
drwxrwxr-x 3 dcminter dcminter 4096 Aug 24 21:56 .
drwxr-x--- 63 dcminter dcminter 4096 Aug 24 21:52 ..
-rw-rw-r-- 1 dcminter dcminter 7208960 Aug 24 21:54 early.cpio
-rw-r--r-- 1 dcminter dcminter 39359954 Aug 24 21:53 initrd.img-6.1.0-21-amd64
-rw-rw-r-- 1 dcminter dcminter 38120498 Aug 24 21:54 main.cpio.gz
drwxrwxr-x 4 dcminter dcminter 4096 Aug 24 21:53 unpacked
Finally I use cat to concatenate the two relevant files into a final initrd file:
dcminter@kanelbulle:~/initrd$ cat early.cpio main.cpio.gz > initrd.dcminter-2024-08-24-6.1.0-21-amd64
dcminter@kanelbulle:~/initrd$ ls -al
total 126992
drwxrwxr-x 3 dcminter dcminter 4096 Aug 24 21:56 .
drwxr-x--- 63 dcminter dcminter 4096 Aug 24 21:52 ..
-rw-rw-r-- 1 dcminter dcminter 7208960 Aug 24 21:54 early.cpio
-rw-rw-r-- 1 dcminter dcminter 45329458 Aug 24 21:56 initrd.dcminter-2024-08-24-6.1.0-21-amd64
-rw-r--r-- 1 dcminter dcminter 39359954 Aug 24 21:53 initrd.img-6.1.0-21-amd64
-rw-rw-r-- 1 dcminter dcminter 38120498 Aug 24 21:54 main.cpio.gz
drwxrwxr-x 4 dcminter dcminter 4096 Aug 24 21:53 unpacked
There’s a size difference between the original 39359954 byte file and my output 45329458 byte file - perhaps that’s the zstd versus
gzip though. Let’s see if the unmkinitramfs tool understands the file I created:
dcminter@kanelbulle:~/initrd$ unmkinitramfs initrd.dcminter-2024-08-24-6.1.0-21-amd64 ./plausible
dcminter@kanelbulle:~/initrd$ cd plausible/
dcminter@kanelbulle:~/initrd/plausible$ ls
early main
Ok, that actually looks quite promising! So next I want to upload my image file to the gateway server and copy
it into /srv/tftp so it can be seen at PXE boot time. Then I edit the /srv/tftp/pxelinux.cfg/default file to
point to the updated initrd file:
DEFAULT linux
LABEL linux
KERNEL vmlinuz-6.1.0-21-amd64
# INITRD initrd.img-6.1.0-21-amd64
INITRD initrd.dcminter-2024-08-24-6.1.0-21-amd64
APPEND root=/dev/nfs nfsroot=192.168.0.254:/clients,rw ip=dhcp nfsrootdebug
Time to reboot the worker node to see if my unpackaged-and-then-repackaged file makes any kind of sense at boot time… aaaaand:
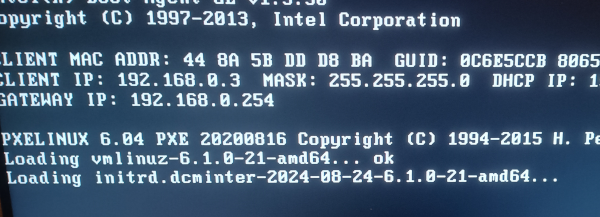
Booting off of my rebuilt image
Yep, it booted ok! The screenshot above shows the image getting recognised, so it’s definitely booting my version and the rest of the boot completed as usual.
So, the next step along the way is to get something unique to each worker node booting - with the main set of operating system files being read-only (so one worker node can’t mess up another) and only the files specific to a given worker being mutable. Let’s take a stab at that…
Worker-specific NFS mounts…
Unfortunately I left rather a long gap between working on this and writing up the following part of it - however I also took a lot of mis-steps in getting here, so the following is a bit less stream-of-consciousness and a bit more in-retrospect-I-did this and that might be for the best.
Steps in initrd
The approach I decided to take for the worker nodes was to boot into an initrd image that would run a script to take the following steps:
- Mount the read-only NFS share to be the root of the node
- Mount
$GATEWAY/clientsas/root- this is part of the existing initrd behaviour - This contains the Debian operating system that the worker nodes are going to be running (as set up in part 3)
- Mount
- Temporarily mount the writeable NFS share
- Mount
$GATEWAY/workersto/workers
- Mount
- Idempotently create a directory specific to the worker node’s network card MAC address within the writeable NFS share
- Create
/workers/$MAC_ADDRESS(which is the same thing as$GATEWAY/workers/$MAC_ADDRESS)
- Create
- Unmount the original writeable NFS share
- Unmount
/workers
- Unmount
- Mount the new worker node specific directory
- Mount
$GATEWAY/workers/$MAC_ADDRESSto/root/var/local
- Mount
- Mount the writeable path for the user home directories
- Mount
$GATEWAY/workers/hometo/root/home
- Mount
- Do some worker node specific config
- Set a hostname based on the MAC address of the node’s network card
- Add that hostname to the hosts file for loopback use
- Write the kernel command line to a file in the
/workers/$MAC_ADDRESSto make it easier to understand the directories that get created on the cluster gateway (the NFS host)
- Carry on the rest of the normal initrd “pivot” process
- This moves everything under
/rootto be under/before handing control to the real init process
- This moves everything under
Here $GATEWAY stands in for the NFS share address of the cluster gateway server, which in reality is 192.168.0.254:
in my setup.
The first part of the setup entails updating the APPEND line in the default.cfg PXE boot configuration to mount the
NFS root read-only:
APPEND root=/dev/nfs nfsroot=192.168.0.254:/clients,ro ip=dhcp nfsrootdebug
Then the idea is that when control is finally handed over to the worker node’s init process the filesystem looks something like this:
/is a read-only mount of$GATEWAY/clients/homeis a writeable mount of$GATEWAY/workers/home(which is shared by all the worker nodes)/var/localis a writeable mount of something like$GATEWAY/workers/448a5bddd8ba
Then in that directory on the cluster gateway of /clients (shared out read-only over NFS to the worker nodes) any
files or directories that need to be writeable will be symlinked to paths in /var/local (so that the init process
and everything it starts can write to them as normal).
This gets a bit convoluted, but for example:
- On the cluster gateway a file
/clients/etc/hostnameis a symlink to/var/local/hostname - This is shared read-only via NFS to the worker node as
/etc/hostname(still a symlink to/var/local/hostname) - On the cluster gateway a file
/workers/448a5bddd8ba/hostnameis shared writeable via NFS to the worker node as/var/local/hostname - On the worker node, therefore,
/etc/hostnameis therefore a symlink to the writeable/var/local/hostnamefile!
I don’t know, that still sounds confusing to me; maybe a diagram will make that clearer…?
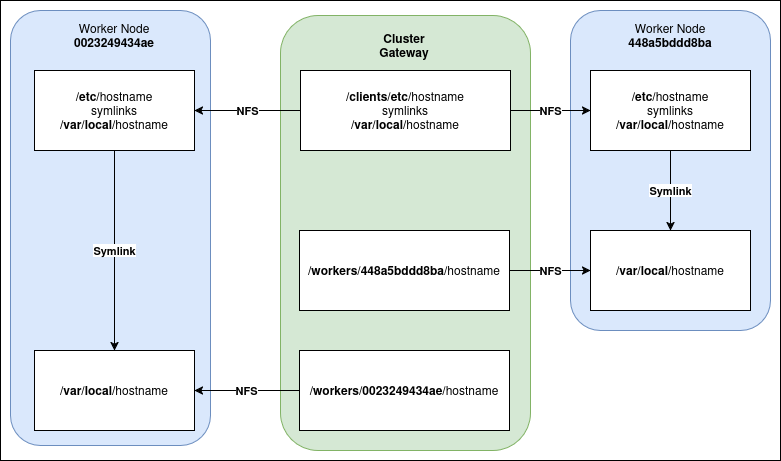
Symlinks to NFS Shares
I did the same thing with /etc/hosts and this gets updated at initrd time as well; various programs expect the
hostname to be resolvable. For example on one of the client nodes the /var/local/hosts file symlinked from
/etc/hosts is as follows:
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
127.0.0.1 worker-node-448a5bddd8ba
::1 worker-node-448a5bddd8ba
The other would be the same but with the hostnames at the foot (for ipv4 and ipv6 respectively)
being worker-node-0023249434ae instead.
I made a few other changes following the Debian read-only root guide:
- I symlinked from
/clients/etc/adjtimeto/var/local/adjtimebut this didn’t seem to have any effect (no adjtime file was created). - I set the
BLKID_FILEenvironment variable in/clients/etc/environmentto/var/local/blkid.tabagain with no apparent effect
I skipped some of the other steps advised there as:
- I’m not going to run courier (imap)
- I’m not going to run cups (the printer support)
- I’m disregarding the LVM stuff for now.
- The Debian filesystem that I have doesn’t actually align with the advice on setting values in
/etc/init.d/hwclockfirst.shand/etc/init.d/hwclock.sh
Getting the MAC address
The Media Access Controller (MAC) address is an identifier specific to a network card - in my case the on-board ethernet controller. This is the identifier I wanted to use for the worker nodes because
- It’s unique per card¹ and therefore per machine
- I can assume it won’t change over time (unlike the IP address for example where the DHCP lease might expire)
- It’s readily available in the context of the initrd boot environment
There are probably various ways I could interrogate the environment even from the limited set of tools inside
the initrd environment, but there’s also an option available from the PXE booting environment - I can add a parameter
to the boot image to make this available on the Linux boot command line. All the parameters set on the boot command
line are available from the procfs filesystem at /proc/cmdline so accessing them is easy from scripts. The
relevant command in the PXE config file is SYSAPPEND which takes a single integer parameter representing a
bitmask indicating what parameters to add to the boot.
I therefore added this line to the /srv/tftp/pxelinux.cfg/default file:
SYSAPPEND 11
This sets 3 bits that cause the following properties to get included in the kernel command line:
- The IP address of the client machine being booted
- The Hardware address (MAC address) of the client machine being booted
- The CPU family & features of the client machine being booted
I included the IP address and the CPU family just in case they turned out to be useful for debugging (in the end I didn’t need them). The important one is the MAC address, but the result is a command line that looks something like this:
dcminter@worker-node-0023249434ae:~$ cat /proc/cmdline
BOOT_IMAGE=vmlinuz-6.1.0-21-amd64 root=/dev/nfs nfsroot=192.168.0.254:/clients,ro ip=dhcp nfsrootdebug initrd=initrd-cluster-24_10_12_23_11_02_CEST ip=192.168.0.4:192.168.0.254:192.168.0.254:255.255.255.0 BOOTIF=01-00-23-24-94-34-ae CPU=6PVXL
Breaking that down into its constituents there are a bunch of fields that are standard for the PXE boot or driven by
the existing APPEND line that also adds items to the boot command line, and then the three extra parameters added
by SYSAPPEND
| Parameter | Value | Note |
|---|---|---|
BOOT_IMAGE |
vmlinuz-6.1.0-21-amd64 |
The kernel image |
root |
/dev/nfs |
The “fake” path that indicates NFS booting |
nfsroot |
192.168.0.254:/clients,ro |
The path to the NFS share to be mounted as root |
ip |
dhcp |
Indicates that DHCP address allocation is in effect |
nfsrootdebug |
none | A flag to enable extra NFS debugging information/behaviour |
initrd |
initrd-cluster-24_10_12_23_11_02_CEST |
The initrd image (adapted by me and containing my scripts) |
ip |
192.168.0.4:192.168.0.254:192.168.0.254:255.255.255.0 |
The actual IP addresses set by DHCP |
BOOTIF |
01-00-23-24-94-34-ae |
The MAC Address of the network card |
CPU |
6PVXL |
A value representing the CPU installed in the booting machine |
The BOOTIF parameter is therefore the relevant one - note that while my hostnames etc are using a value
like 0023249434ae this doesn’t exactly match the 01-00-23-24-94-34-ae value shown here; what’s that about?
The first two digits of the BOOTIF parameter actually indicate the (hardware) network type - in this case ARP type 1
which is Ethernet. Since I’m
only ever going to be using Ethernet this is redundant and I decided to remove it. I also remove the hyphens, and the
result is the shorter 12 character value that I’ve then used for the hostname and the corresponding worker node
directories.
In my script I extract that from the /proc/cmdline with the following monster sed script:
SUFFIX=$(/bin/sed 's/.*BOOTIF=\(..\-..\-..\-..\-..\-..\-..\).*/\1/' /proc/cmdline | /bin/sed 's/..\-\(..\)\-\(..\)\-\(..\)\-\(..\)\-\(..\)\-\(..\)/\1\2\3\4\5\6/')
On reflection there’s probably some much cleaner way to do that, but this worked for me and I probably won’t change it unless I find a problem with the approach.
About those scripts…
The initrd image used by Debian is not all that well documented. A bunch of things allude to it, but once you want to change things there’s not much to help you. No I did not ask Chat GPT and no I do not intend to. Just don’t.
When you poke around in it there are also quite a lot of “TODO” comments of various types, so it feels like it’s just good enough for purpose and so doesn’t get a lot of love. At least that means I feel less weird about intruding my own sketchy stuff into it!
Figuring out what’s what is fairly easy, though, because the initrd image is launched from the kernel and therefore there needs to be an init entry point of some type - and in practice that init entry point is itself a script (and in fact this is how things used to work generally before the initramfs approach existed). So an editor and a bit of poking in the init script and its children is all I needed to find my way around. The main thing I wanted was a place where I could make my own worker node changes to take effect just before handing over control to the normal but read-only OS root init process.
The init script in the root of the initrd image (or at least the part of it that’s not got the CPU microcode
images in it!) launches various dependent scripts by directory - the last ones kicked off before the handover to
the “real” init process are under scripts/init-bottom and it doesn’t explicitly dictate which ones to run; instead
each of these scripts directories contains an ORDER script that indicates what to run, so I added mine here to be
the last to run.
Here’s my amended scripts/init-bottom/ORDER file:
/scripts/init-bottom/udev "$@"
[ -e /conf/param.conf ] && . /conf/param.conf
/scripts/init-bottom/mount_node_nfs "$@"
[ -e /conf/param.conf ] && . /conf/param.conf
The udev script already existed and mine is the mount_node_nfs script. I think the additional lines ensure that
any configuration changes written by the scripts are then made available as environment variables to scripts that run
after these were invoked. I don’t use that in mine, but I tried to keep it consistent with what already existed.
Debugging scripts in initrd
To aid in debugging the various config changes I was making, and in order to ensure I was even executing my script
at all, I added some output to the kernel message buffer. This is nice because to write to it I can just send text to
/dev/kmsg and anything I write there will be available via dmesg as long as I have some kind of interactive
access (even inside the initrd busybox environment) to issue the dmesg command.
If you’re not familiar with this, give it a go - as root echo something to /dev/dmsg and then run dmesg and you’ll
see it in the output.
So my initial script just looked something like this:
#!/bin/sh -e
function kprint() {
echo "dcminter: $1" > /dev/kmsg
}
kprint 'We ran a boot script after mounting root'
After rebuilding the initrd image, putting it in the tftp server, and amending the PXE config to point to the updated file and then booting successfully…
$ sudo su -
[sudo] password for dcminter:
root@worker-node:~# dmesg | grep dcminter
[ 8.885289] dcminter: We ran a boot script after mounting root
So that’s good enough to be useful - every time I screwed something up to the point where it wouldn’t boot any more I would back up a bit, dump things I expected to be true to the kernel message buffer, and then figure out where my expectations were broken. It was a lot less painful than I expected!
The actual script
Here’s the actual full version of mount_node_nfs that I ended up with:
dcminter@kanelbulle:~/initrd/unpacked/main/scripts/init-bottom$ cat mount_node_nfs
#!/bin/sh -e
function kprint() {
echo "dcminter: $1" > /dev/kmsg
}
function nfs_mount_node() {
kprint 'About to attempt to mount the node share on nfs'
kprint "Boot variable is $BOOTIF"
kprint "rootmnt is $rootmnt"
SUFFIX=$(/bin/sed 's/.*BOOTIF=\(..\-..\-..\-..\-..\-..\-..\).*/\1/' /proc/cmdline | /bin/sed 's/..\-\(..\)\-\(..\)\-\(..\)\-\(..\)\-\(..\)\-\(..\)/\1\2\3\4\5\6/')
kprint "Target hostname directory has suffix $SUFFIX"
kprint "Dumping boot commandline"
cat /proc/cmdline > /dev/kmsg
# Note - Anything mounted under /root will be under / after the pivot!
kprint "Create the node directory under the /workers share"
mkdir -p /workers # Mount ephemerally - this mountpoint intentionally won't be around after the pivot!
nfsmount -o rw 192.168.0.254:/workers /workers
kprint "Creating the node's directory if it does not already exist"
mkdir -p /workers/$SUFFIX
umount /workers
kprint "Unmounted /workers"
kprint "Mounting /workers/home to /root/home in preparation for pivot"
nfsmount -o rw 192.168.0.254:/workers/home /root/home
kprint "Mounted /root/home"
kprint "Mount the node's directory as the writeable /root/var/local"
nfsmount -o rw 192.168.0.254:/workers/$SUFFIX /root/var/local
kprint "Mounted /root/workers"
# Set the hostname (and make it sticky)
kprint "Set the hostname"
hostname "worker-node-$SUFFIX"
echo "worker-node-$SUFFIX" > /root/var/local/hostname
kprint "Hostname should be worker-node-$SUFFIX now"
kprint "Adding loopback resolution for hostname"
cp /etc/hosts /root/var/local/hosts
echo "127.0.0.1 worker-node-$SUFFIX" >> /root/var/local/hosts
echo "::1 worker-node-$SUFFIX" >> /root/var/local/hosts
kprint "Appropriate hosts file created."
kprint "Write cmdline to var mount to make ip address identification easier from outside the worker node"
cat /proc/cmdline > /root/var/local/cmdline
kprint "Written cmdline"
}
kprint 'We ran a boot script after mounting root'
nfs_mount_node
And here’s the relevant output from dmesg for that:
[ 8.885289] dcminter: We ran a boot script after mounting root
[ 8.885383] dcminter: About to attempt to mount the node share on nfs
[ 8.885456] dcminter: Boot variable is 01-00-23-24-94-34-ae
[ 8.885525] dcminter: rootmnt is /root
[ 8.886750] dcminter: Target hostname directory has suffix 0023249434ae
[ 8.886828] dcminter: Dumping boot commandline
[ 8.887428] BOOT_IMAGE=vmlinuz-6.1.0-21-amd64 root=/dev/nfs nfsroot=192.168.0.254:/clients,ro ip=dhcp nfsrootdebug initrd=initrd-cluster-24_10_12_23_11_02_CEST ip=192.168.0.4:192.168.0.254:192.168.0.254:255.255.255.0 BOOTIF=01-00-23-24-94-34-ae CPU=6PVXL
[ 8.887669] dcminter: Create the node directory under the /workers share
[ 8.893085] dcminter: Creating the node's directory if it does not already exist
[ 8.936997] dcminter: Unmounted /workers
[ 8.937073] dcminter: Mounting /workers/home to /root/home in preparation for pivot
[ 8.942253] dcminter: Mounted /root/home
[ 8.942328] dcminter: Mount the node's directory as the writeable /root/var/local
[ 8.973783] dcminter: Mounted /root/workers
[ 8.973856] dcminter: Set the hostname
[ 8.977181] dcminter: Hostname should be worker-node-0023249434ae now
[ 8.977257] dcminter: Adding loopback resolution for hostname
[ 8.981296] dcminter: Appropriate hosts file created.
With this script in place, I was able to boot two distinct client worker nodes, with their own distinct writeable directories for config information, a shared read-only root directory, and shared user home directories - with no local filesystem at all - everything is accessed over NFS (in particular no RAM based filesystem).
Pivot
One thing that’s worth mentioning there is the “pivot” thing. This sounds fancy but it’s actually very simple. When
the initrd image starts, the / directory is a ram disk overlaid on top of the contents of the packed up initrd image.
Nothing written to it is permanent. The root device passed in on the boot commands is mounted to /root and at least
in the case of an NFS root this is actually done by some of the scripts kicked off by the init script itself.
When all the scripts have finished running, however, the ramdisk / is replaced by the /root mount - this is
the “pivot” in question. So if a file is located at /etc/foo after everything is finished, then before that it will
instead be available at /root/etc/foo within the initrd environment.
That’s why, for example, the per-workstation share is mounted to /root/var/local instead of directly
to /var/local in my script - after the pivot that’s where it will end up.
Repeatedly building initrd
I’ll just mention in passing that while this went more smoothly than I expected, it wasn’t completely clear sailing and I ended up recreating the initrd image at least a dozen (probably more) times. To aid in this I scripted most of the steps to re-create that. I’ll share that setup here:
In an initrd on my laptop I’d created the following directories and files:
unpackedcontained the unpacked Debian initrd image, within which wereearlythe microcode files, which I didn’t need to change (not used in this process)mainthe actual initrd environment where the scripts etc resided - these are the files I was changing
outputa directory to contain the initrd images I would be buildingearly.cpiothe packed up microcode files archive that I created in the preparing to customise the initramfs image section above.build.sha script to rebuild the initrd image
The build.sh script is then:
#!/bin/bash
#
export HERE=$PWD
cd $HERE/unpacked/main
find . -print0 | cpio --null --create --verbose --format=newc > $HERE/main.cpio
cd $HERE
echo 'Compressing...'
gzip --best --force main.cpio
cat early.cpio main.cpio.gz > output/initrd-cluster-$(date '+%y_%m_%d_%H_%M_%S_%Z')
It has to be run from the unpacked directory, and it will pack up and compress the (modified) files
under unpacked/main, concatenate them with the microcode archive, and put the result into an output directory
with a datestamped filename.
I left the rest of the process manual with the steps being to:
- Upload the new initrd file via sftp to the
/srv/tftpdirectory of the cluster gateway server - Edit the
/srv/tftp/pxelinux.cfgfile to have theINITRDentry point to the new file - Reboot one of the worker nodes to see how it went
I’d have automated that last part as well if I’d ended up doing it just a few more times as it got fairly tedious once I was just making small and frequent tweaks to the script.
The NFS shares from the gateway perspective
To support the necessary shares for all that the exports file on the cluster gateway ended up containing
the following shares (not forgetting to update the exports with exportfs -ra or rebooting):
/clients 192.168.0.0/255.255.255.0(ro,no_root_squash,no_subtree_check,async)
/workers 192.168.0.0/255.255.255.0(rw,no_root_squash,no_subtree_check,async)
After booting a couple of nodes, it I go to the cluster gateway and view the contents of the /workers share…
dcminter@cluster-gateway:~$ sudo tree /workers
/workers
├── 0023249434ae
│ ├── hostname
│ └── hosts
├── 448a5bddd8ba
│ ├── hostname
│ └── hosts
└── home
├── dcminter
└── root
6 directories, 4 files
Lest you doubt me…
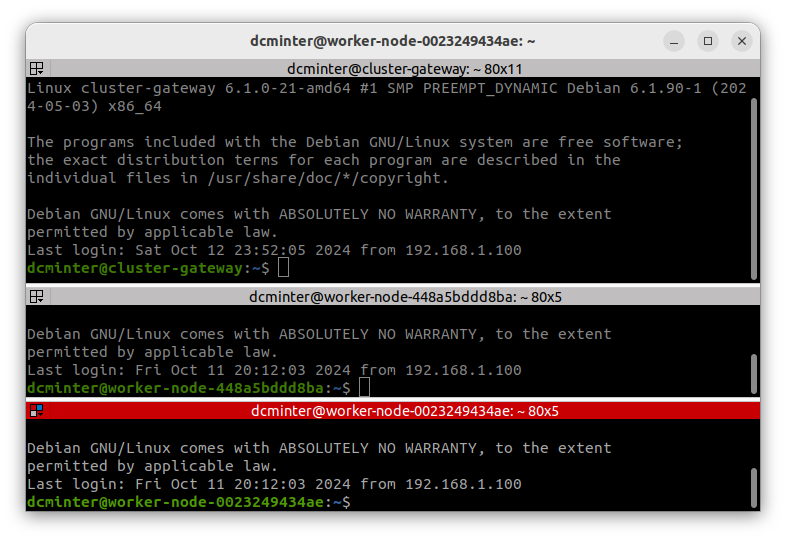
Independently booted instances!
W00t! Sorry about those timestamps though - it really was a long time before I got around to the write-up! Nearly six months in fact. Oops.
Puzzling pings…
With all this set up I encountered one interesting problem almost immediately - ping stopped working. This is kind of a basic tool so I had to get to the bottom of that…
Here’s the symptom:
dcminter@worker-node-448a5bddd8ba:~$ ping 127.0.0.1
ping: socktype: SOCK_RAW
ping: socket: Operation not permitted
ping: => missing cap_net_raw+p capability or setuid?
Ok, so I hopped onto the cluster gateway and set the SUID bit (4775) on the shared ping binary:
dcminter@worker-node-448a5bddd8ba:~$ ping 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.017 ms
^C
--- 127.0.0.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.017/0.017/0.017/0.000 ms
That worked. Prior to that it also worked if I did su or sudo first. That took me a hot minute, but it turned out that ping was granted access to the hoi polloi (i.e. non root users) via “capabilities” settings in the filesystem - and these don’t actually work over NFS (or don’t work over NFS the way I currently have it set up).
Here’s what’s set over on the raw filesystem:
dcminter@cluster-gateway:/clients/bin$ sudo getcap /clients/bin/ping
/clients/bin/ping cap_net_raw=ep
The cluster gateway’s own ping (the same original Debian bookworm origins) binary comes from the iputils-ping package:
dcminter@cluster-gateway:/clients/bin$ dpkg-query -S /bin/ping
iputils-ping: /bin/ping
Ok, so what does the code say?
Kernel returns
EACCESfor all ping socket creation attempts when the user isn’t allowed to use ping socket. A range of group ids is configured using thenet.ipv4.ping_group_rangesysctl. Fallback to raw socket is necessary.Kernel returns
EACCESfor all raw socket creation attempts when the process doesn’t have theCAP_NET_RAWcapability.
So that figures given that NFS (at least as I set it up) doesn’t support the capability feature. For now the suid bit will do fine I guess. I wonder if there are any other important binaries that are going to have this issue though 🤔
Contacts…
During the loooong gap between me finishing the write-up of part 3 and this write-up of part 4 I had a couple of nice contacts:
- Walid 👋 dropped me a line to say he was doing something similar - he ended up using a tool called dracut - but at this point I’d more or less got my current approach working and I’m too stubborn to change tack. For now.
- Then I also had a brief message from Hanno 👋 who found the PXE boot stuff in the previous section interesting.
That was really nice; thanks guys! It’s fun to know that my stuff isn’t entirely write-only. I’ll probably share it on HN as well once I have the cluster finished so that all the Linux & Kubernetes experts can tell me where I’m going wrong. If it gets any traction (always a total lottery) that’ll be pretty interesting (and humbling) I’m sure; I’m only doing it for fun, so it doesn’t matter, but I do feel like there’s probably some much simpler way to achieve all this!
Next
Alright, that’s a lot, but it’s useful progress. I’m not quite ready for the Kubernetes stuff - although these
worker nodes are booting up ok and are usable there are some things that aren’t going to be working quite right yet.
For example I know that my logs aren’t getting written to /var/log … because that’s still part of the read-only
root filesystem. I want to flush out that and any other issues I can find in the next part so that I’ve got a
fairly solid base on which to proceed with the Kubernetes setup.
One other thing I’m pondering for part 5 is whether I ought to set up /var/log to just be another part of the
per-node shares, or whether it would be better to do syslog over the network… if you have thoughts or knowledge
on that topic, do let me know.
I might well take a break from this series to do one or more short posts that I’ve had in mind for a while but put-off while this one was half-finished; we’ll see. One of them, ironically, is about the many unfinished projects I have in the air at any given time!
Anyway, I definitely want to make this setup more stable before I proceed with the Kubernetes stuff because I assume setting up Kubernetes is going to be tricky and I’d prefer to avoid having to figure out whether things are breaking because I screwed up the OS config or because I screwed up the Kubernetes config!
Some more handy resources
- https://wiki.debian.org/ReadonlyRoot
- https://www.iram.fr/~blanchet/tutorials/read-only_diskless_debian10.pdf
- https://unix.stackexchange.com/questions/741635/what-happens-to-the-files-in-directories-mounted-by-initrd-when-initrd-unmount
- https://github.com/iputils/iputils/blob/master/ping/ping.c
- https://opennms.discourse.group/t/how-to-allow-unprivileged-users-to-use-icmp-ping/1573
Footnotes
¹ As usual, this isn't entirely true. The MAC address can usually be changed via the BIOS (I haven't tried) and part of the MAC address actually encodes (or used to) the manufacturer - which meant that sketchy hardware makers would sometimes re-use an existing manufacturer prefix creating the risk that their cards would actually have colliding MAC addresses. In practice all mine are legit intel hardware and I don't plan to change them in BIOS so this is good enough for me.